RAG
RAG is Retrieval Augmented Generation
RAG is an innovative approach in the field of NLP that combines the strength of 2 models i.e retrieval based model and generation based model to enhance the quality of generated text.
Eg. You give prompt to say ChatGPT and it gives you response. That response is generated by a model using context from the information retrieved by another model.
Why is RAG important?
Always remember a new approach comes only when there is a limitation.
There is a limitation with the traditional LLM’s. They generate response based solely on the data it is trained on. But for the response we may need current information as well as some specific details required for certain tasks.
RAG addresses this limitation by incorporating a retrieval mechanism that allow the model to access external databases or documents in real-time.
Eg. A financial model may be trained on last 52 weeks stocks data but to provide accurate response it is necessary for it know the current stock price too.
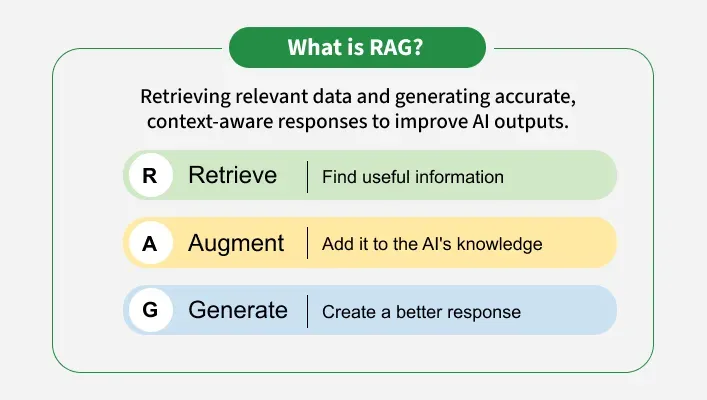
How does RAG work?

Steps:
- Information retrieved from the external knowledge source. [Retrieval]
- Augmenting this information(context) with the user’s query. [Augmenting]
- Generating accurate and contextually relevant response using LLM. [Generation]
What problems does RAG solve?
- Factual Inaccuracies and Hallucinations
- Outdated Information
- Contextual Relevance
- Domain-specific knowledge
- Cost and Efficiency - Fine-tuning large models for specific tasks is expensive. RAG eliminates the need for retraining by dynamically retrieving relevant data, reducing costs and computational load.
- Scalability across domains - RAG is adaptable to diverse industries, from healthcare to finance, without extensive retraining, making it highly scalable
Challenges
- Complexity: Combining retrieval and generation adds complexity to the model, requiring careful tuning and optimization to ensure both components work seamlessly together.
- Latency: The retrieval step can introduce latency, making it challenging to deploy RAG models in real-time applications.
- Quality of Retrieval: The overall performance of RAG heavily depends on the quality of the retrieved documents. Poor retrieval can lead to suboptimal generation, undermining the model’s effectiveness.
- Bias and Fairness: Like other AI models, RAG can inherit biases present in the training data or retrieved documents, necessitating ongoing efforts to ensure fairness and mitigate biases.